复制-- 命中索引 SELECT * FROM orders WHERE user_id = 1001 AND status = PAID; -- 命中索引(最左前缀) SELECT * FROM orders WHERE user_id = 1001; -- 未命中索引(违反最左前缀) SELECT * FROM orders WHERE status = PAID;1.2.3.4.5.6.7.8.9.10.11.
复制EXPLAIN SELECT order_no, amount FROM orders WHERE user_id = 1001 AND status = PAID;1.2.3.
执行计划:
复制| id | select_type | table | type | key | Extra | |----|-------------|--------|------|-------------------|-------------| | 1 | SIMPLE | orders | ref | idx_user_status | Using where|1.2.3.
使用覆盖索引:
复制-- 创建覆盖索引 CREATE INDEX idx_covering ON orders(user_id, status, order_no, amount); EXPLAIN SELECT order_no, amount FROM orders WHERE user_id = 1001 AND status = PAID;1.2.3.4.5.6.
执行计划:
复制| id | select_type | table | type | key | Extra | |----|-------------|--------|------|--------------|--------------------------| | 1 | SIMPLE | orders | ref | idx_covering | Using index |1.2.3.
性能对比:覆盖索引减少磁盘I/O,查询速度提升5-10倍。
五、数据类型优化
数据类型优化,它是索引大小的隐形杠杆。
常见类型空间占用:
数据类型
字节数
索引大小(百万行)
BIGINT
8
15MB
INT
4
7.5MB
MEDIUMINT
3
5.6MB
CHAR(32)
32
61MB
VARCHAR(32)
变长
20-50MB
优化案例:
复制-- 优化前:使用字符串存储IP CREATETABLE access_log ( idBIGINT, ip VARCHAR(15), INDEX idx_ip (ip) ); -- 优化后:转换为整型存储 CREATETABLE access_log ( idBIGINT, ip INTUNSIGNED, INDEX idx_ip (ip) );1.2.3.4.5.6.7.8.9.10.11.12.13.
空间节省:IP字段索引大小从78MB降至12MB,内存命中率提升40%。
六、函数陷阱
函数陷阱,它是索引失效的元凶。
索引失效案例:
复制-- 创建索引 CREATE INDEX idx_create_time ON orders(create_time); -- 索引失效查询 SELECT * FROM orders WHERE DATE_FORMAT(create_time, %Y-%m-%d) = 2023-06-01; -- 优化后查询 SELECT * FROM orders WHERE create_time BETWEEN 2023-06-01 00:00:00 AND 2023-06-01 23:59:59;1.2.3.4.5.6.7.8.9.10.
函数使用原则:
复制graph LR A[查询条件] --> B{是否包含函数} B -->|是| C[索引可能失效] B -->|否| D[正常使用索引] C --> E[重写条件] E --> D1.2.3.4.5.6.
性能对比:日期范围查询优化后,执行时间从1200ms降至15ms。
七、前缀索引
前缀索引,它是大文本字段的救星。
创建方法:
复制-- 原始字段索引 CREATE INDEX idx_product_desc ON products(description); -- 无法创建,text字段过大 -- 前缀索引 CREATE INDEX idx_product_desc_prefix ON products(description(20));1.2.3.4.5.
长度选择算法:
复制-- 计算最佳前缀长度 SELECT COUNT(DISTINCT LEFT(description, 10)) / COUNT(*) AS selectivity10, COUNT(DISTINCT LEFT(description, 20)) / COUNT(*) AS selectivity20, COUNT(DISTINCT LEFT(description, 30)) / COUNT(*) AS selectivity30 FROM products;1.2.3.4.5.6.
复制-- 查看未使用索引 SELECT object_schema, object_name, index_name FROM performance_schema.table_io_waits_summary_by_index_usage WHERE index_name IS NOT NULL AND count_star = 0 AND object_schema NOT IN (mysql, sys);1.2.3.4.5.6.7.8.9.
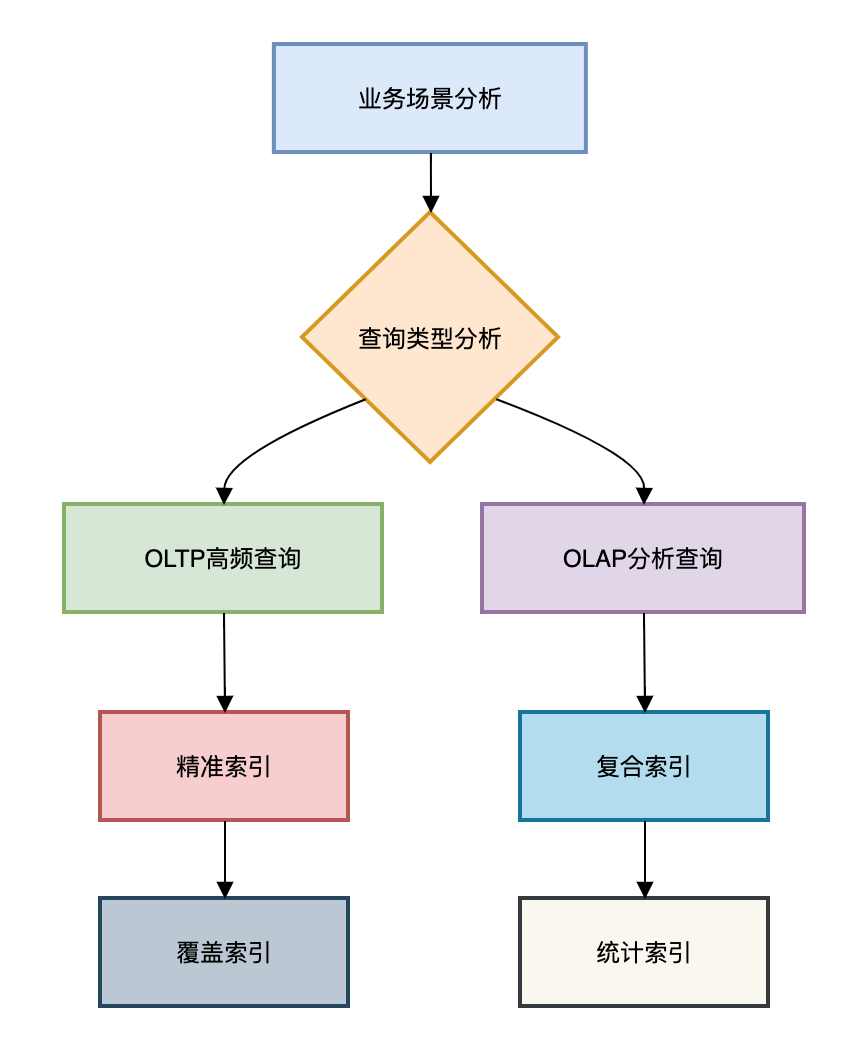

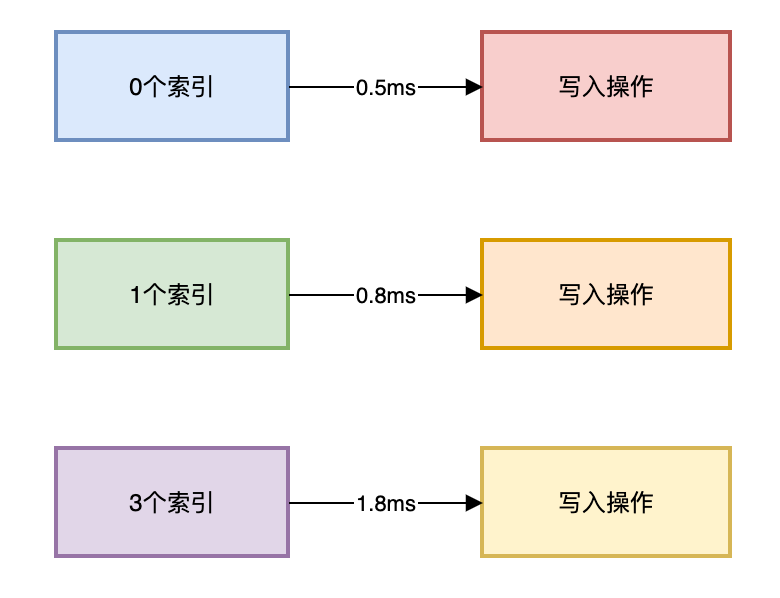
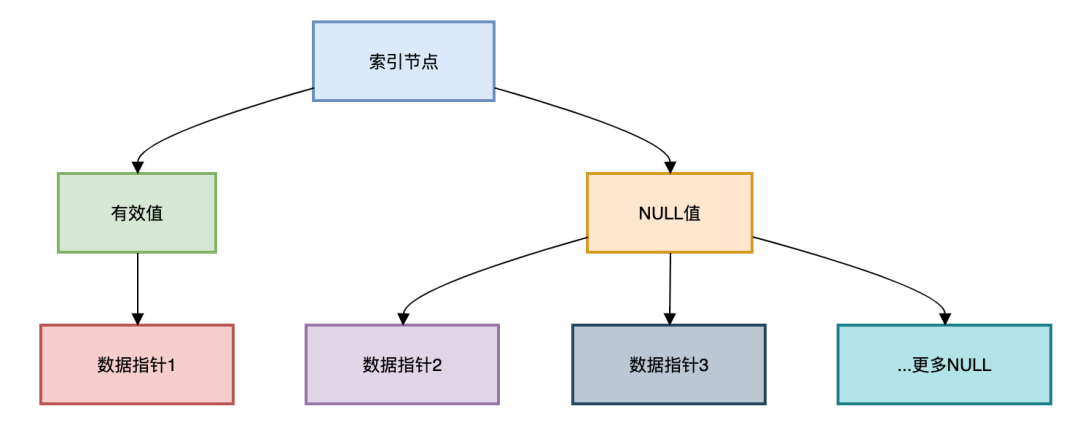 图片
图片 图片
图片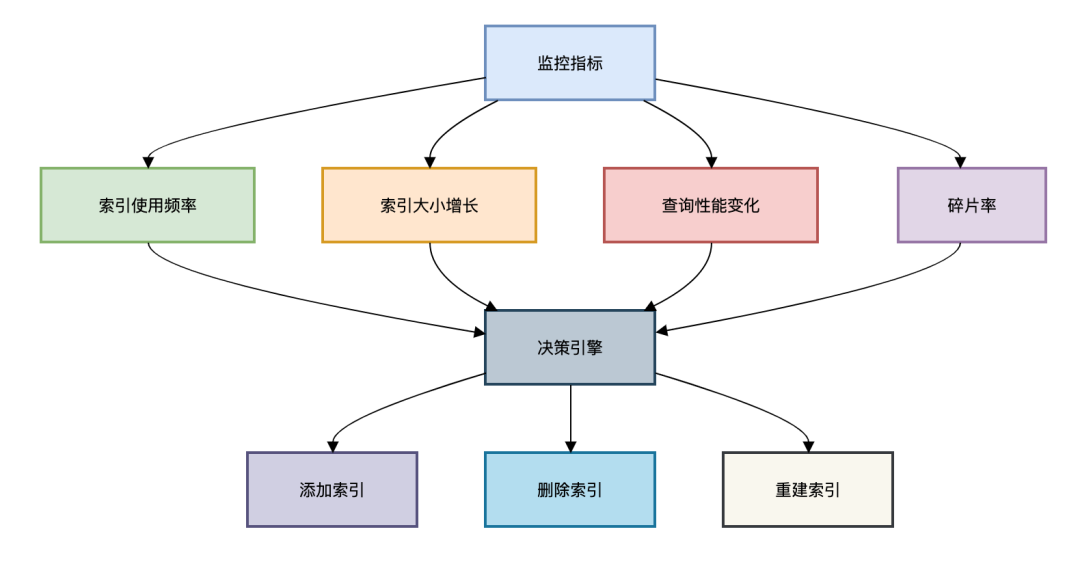 图片
图片 亿华智慧云
亿华智慧云
